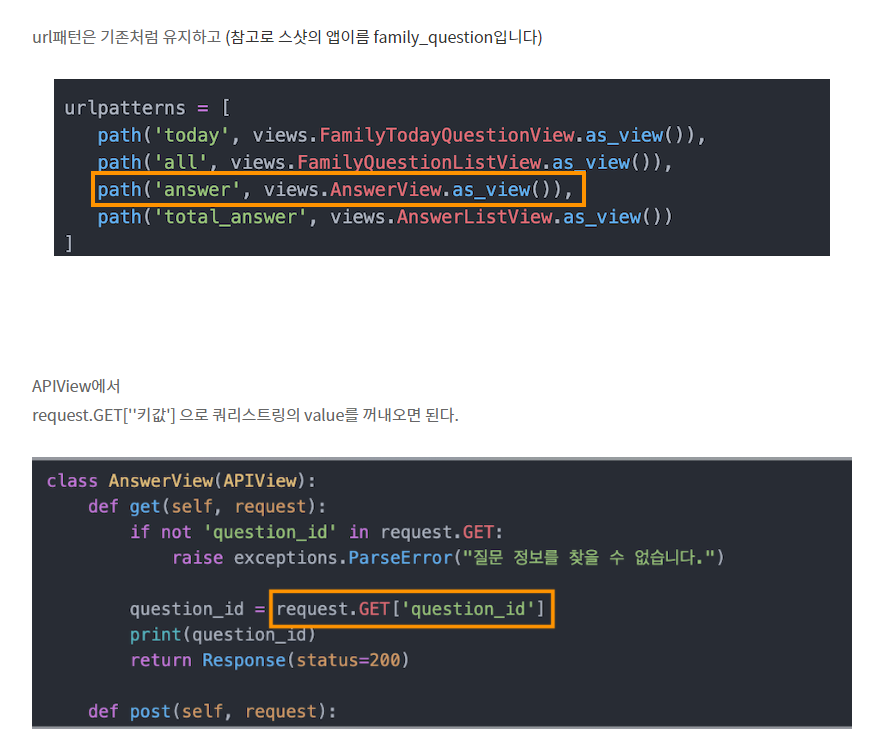
클라이언트별 정보를 브라우저가 아닌 웹서버에 저장하는 것입니다. 클라이언트의 정보를 웹브라우저에 저장하는 기술을 cookie라고 하죠. django의 session은 쿠키에는 sessionId만을 저장하여, 클라이언트와 웹서버간의 연결성을 확보한뒤 sessionId를 통해 커뮤니케이션을 실행합니다. session의 라이프사이클은 브라우저에 의존합니다. 같은 브라우저를 사용하고 있다면 링크를 통해서 다른 사이트로 이동할때도 sessionId는 쿠키로써 쭉 유지되고, 브라우저를 닫으면 사라집니다.
Session의 원리
유저가 웹사이트에 접속
웹사이트의 서버가 유저에게 sessionId를 부여
유저의 브라우저가 이 sessionId를 cookie에 보존
통신할때마다 sessionId를 웹서버에 전송(따라서 django의 경우 request객체에 sessionId가 들어있음)
# Get a session value by its key (e.g. 'my_car'), raising a KeyError if the key is not present
my_car = request.session['my_car']
# Get a session value, setting a default if it is not present ('mini')
my_car = request.session.get('my_car', 'mini')
# Set a session value
request.session['my_car'] = 'mini'
# Delete a session value
del request.session['my_car']
request.session 은 아래와 같이 프린트 된다. 중요한건 아닌데 궁금해서 찍어보았다.
<django.contrib.sessions.backends.db.SessionStore object at 0x7f8d3382a850>
request.session 은 각 키마다 값을 가지고 있는 dictionary 와 비슷한 형태라고 알고 있자.
def post_comment(request, new_comment):
if request.session.get('has_commented', False):
#('has_commented' 라는 key 가 있다면 value 를 return 하고, 아니면 False 를 return 합니다.)
return HttpResponse("You've already commented.")
c = comments.Comment(comment=new_comment)
c.save()
request.session['has_commented'] = True
return HttpResponse('Thanks for your comment!')
def login(request):
m = Member.objects.get(username=request.POST['username'])
if m.password == request.POST['password']:
request.session['member_id'] = m.id
return HttpResponse("You're logged in.")
else:
return HttpResponse("Your username and password didn't match.")
def logout(request):
try:
del request.session['member_id']
except KeyError:
pass
return HttpResponse("You're logged out.")
중간에 {{}}은 {{#posts}}에서 List를 순회화면서 받은 값들을 뿌려주는 것이다.
그리고 PostsRepository에서 받아오는 거니까
import java.util.List;
public interface PostsRepository extends JpaRepository<Posts,Long> {
@Query("SELECT p FROM Posts p ORDER BY p.id DESC")
List<Posts> findAllDesc();
}
@query문이 추가된다.
그리고 PostsService에서 Transaction을 추가해준다.
@Transactional(readOnly = true)
public List<PostsListResponseDto> findAllDesc(){
return postsRepository.findAllDesc().stream()
.map(PostsListResponseDto::new) //.map(posts -> new PostsListResponseDto(posts))와 같음
.collect(Collectors.toList());
}
그리고 출력할 양식이 필요하니 Dto를만들어준다. -> PostsListResponseDto
@Getter
public class PostsListResponseDto {
private Long id;
private String title;
private String author;
private LocalDateTime modifiedDate;
public PostsListResponseDto(Posts entity){
this.id = entity.getId();
this.title = entity.getTitle();
this.author = entity.getAuthor();
this.modifiedDate = entity.getModifiedDate();
}
}
1) 특정 페이지가 요청(리퀘스트)되면, 장고는 요청 시 메타데이터를 포함하는 HttpRequest 객체를 생성 2) 장고는 urls.py에서 정의한 특정 View 클래스/함수에 첫 번째 인자로 해당 객체(request)를 전달 3) 해당 View는 결과값을 HttpResponse 혹은 JsonResponse 객체에 담아 전달
1. HTTPRequest
- 주요 속성(Attribute)
HttpRequest.body # request의 body 객체
HttpRequest.headers # request의 headers 객체
HttpRequest.COOKIES # 모든 쿠키를 담고 있는 딕셔너리 객체
HttpRequest.method # reqeust의 메소드 타입
HttpRequest.GET # GET 파라미터를 담고 있는 딕셔너리 같은 객체
HTTpRequest.POST # POST 파라미터를 담고 있는 딕셔너리 같은 객체
- 활용
request.method
if request.method == 'GET':
do_something()
elif request.method == 'POST':
do_something_else()
request.headers 가져오기
{'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6', ...}
>>> 'User-Agent' in request.headers
True
>>> 'user-agent' in request.headers
True
>>> request.headers['User-Agent']
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
>>> request.headers['user-agent']
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
>>> request.headers.get('User-Agent')
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
>>> request.headers.get('user-agent')
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
2. HttpResponse
HttpResponse(data, content_type)
response를 반환하는 가장 기본적인 함수
주로 html를 반환
# string 전달하기
HttpResponse("Here's the text of the Web page.")
# html 태그 전달하기
response = HttpResponse()
>>> response.write("<p>Here's the text of the Web page.</p>")
3. HttpRedirect
HttpResponseRedirect(url)
별다른 response를 하지는 않고, 지정된 url페이지로 redicrect를 함
첫번 째 인자로 url를 반드시 지정해야 하며, 경로는 절대경로 혹은 상대경로를 이용할 수 있음
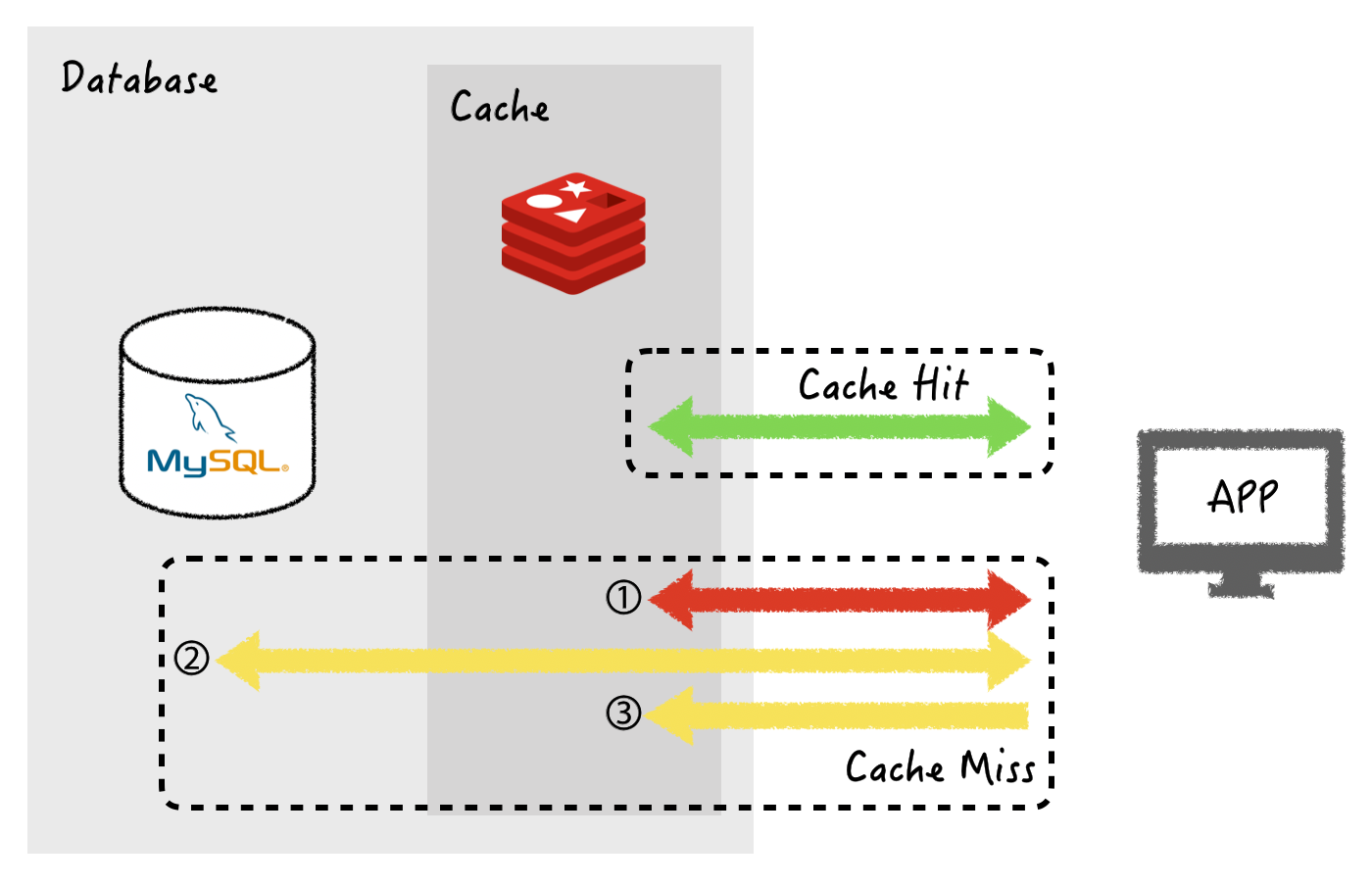
이름에서 알 수 있듯이 이 구조는 캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 캐싱 전략입니다. 캐시는 데이터베이스와 어플리케이션 사이에 위치하여 단순 key-value 형태를 저장합니다. 어플리케이션에서 데이터를 가져올 때 레디스에 항상 먼저 요청하고, 데이터가 캐시에 있을 때에는 레디스에서 데이터를 반환합니다. 데이터가 캐시에 없을 경우 어플리케이션에서 데이터베이스에 데이터를 요청하고, 어플리케이션은 이 데이터를 다시 레디스에 저장합니다. 아래 그림은 이 프로세스를 나타내고 있습니다.
위 구조를 사용하면실제로 사용되는 데이터만 캐시할 수 있고,레디스의 장애가 어플리케이션에 치명적인 영향을 주지 않는다는 장점을 가지고 있습니다.하지만 캐시에 없는 데이터를 쿼리할 때 더 오랜 시간이 걸린다는 단점과 함께, 캐시가 최신 데이터를 가지고 있다는 것을 보장하지 못하는 단점이 있습니다. 캐시에 해당 key 값이 존재하지 않을 때만 캐시에 대한 업데이트가 일어나기 때문에 데이터베이스에서 데이터가 변경될 때에는 해당 값을 캐시가 알지 못하기 때문입니다.
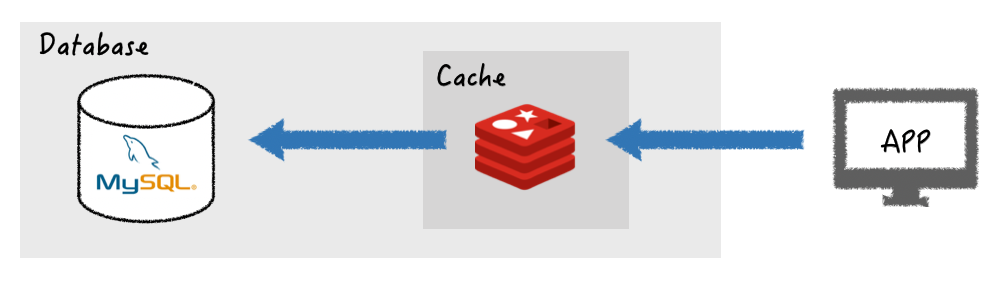
2. Write-Through
Write-Through구조는 데이터베이스에 데이터를 작성할 때마다 캐시에 데이터를 추가하거나 업데이트합니다. 이로 인해캐시의 데이터는 항상 최신 상태로 유지할 수 있지만, 데이터 입력 시 두번의 과정을 거쳐야 하기 때문에 지연 시간이 증가한다는 단점이 존재합니다. 또한 사용되지 않을 수도 있는 데이터도 일단 캐시에 저장하기 떄문에 리소스 낭비가 발생합니다. 이를 해결하기 위해 데이터 입력시TTL을 꼭 사용하여 사용되지 않는 데이터를 삭제하는 것을 권장합니다.
Redis의 활용사례
1. 좋아요 처리하기
가장 중요한 것은 한 사용자가하나의 댓글에 한번만좋아요를 할 수 있도록 제한하는 것입니다. RDBMS에서는 유니크 조건을 생성해서 처리할 수 있습니다. 하지만 만약 많은 입력이 발생하는 환경에서 RDBMS을 이용한다면 insert와 update에 의한 성능 저하가 필연적으로 발생하게 됩니다
레디스의set을 이용하면 이 기능을 간단하게 구현할 수 있으며, 빠른 시간 안에 처리할 수 있습니다. set은 순서가 없고, 중복을 허용하지 않는 집합입니다. 댓글의 번호를 사용해서 key를 생성하고, 해당 댓글에 좋아요를 누른 사용자의 ID를 아이템으로 추가하면 동일한 ID값을 저장할 수 없으므로 한 명의 사용자는 하나의 댓글에 한번만 좋아요를 누를 수 있게 됩니다.
2. 게임 서비스 일일 순방문자수 구하기
순 방문자수(UV)는 서비스에 사용자가 하루에 여러번 방문했다 하더라도 한번만 카운팅되는 값입니다. 즉중복 방문을 제거한 방문자의 지표라고 생각할 수 있습니다. 많은 서비스에서 이 수치를 이용해 사용자의 동향을 파악하고, 마케팅을 위한 자료로 활용하기도 합니다.
실제 서비스에서는 이를 구하기 위해서 대표적으로 세 가지 방법을 사용합니다. 첫번째로 액세스 로그(access log)를 분석하는 방법, 두번째로 외부 서비스(ex. Google Analytics)의 도움을 받는 방법, 세번째로는 접속 정보를 로그파일로 작성하여 배치 프로그램으로 돌리는 방법입니다. 이 세 가지 방법 중 GA를 제외하고는 정보를 실시간으로 조회할 수 없습니다.
그렇다면 이제 레디스의 비트 연산을 활용하여 간단하게 실시간 순 방문자를 저장하고 조회하는 방법을 알아보겠습니다. 게임의 유저는 천만명이라 가정하고, 일일 방문자 횟수를 집계하며 이 값은 0시를 기준으로 초기화됩니다.
사용자 ID는 0부터 순차적으로 증가된다고 가정하고, string의 각 bit를 하나의 사용자로 생각할 수 있습니다.사용자가 서비스에 방문할 때 사용자 ID에 해당하는 bit를 1로 설정합니다. 1개의 bit가 1명을 의미하므로,천만명의 유저는 천만개의 bit로 표현할 수 있고, 이는 곧 1.2MB정도의 크기입니다. 레디스 string의 최대 길이는 512MB이므로 천만명의 사용자를 나타내는건 충분합니다.
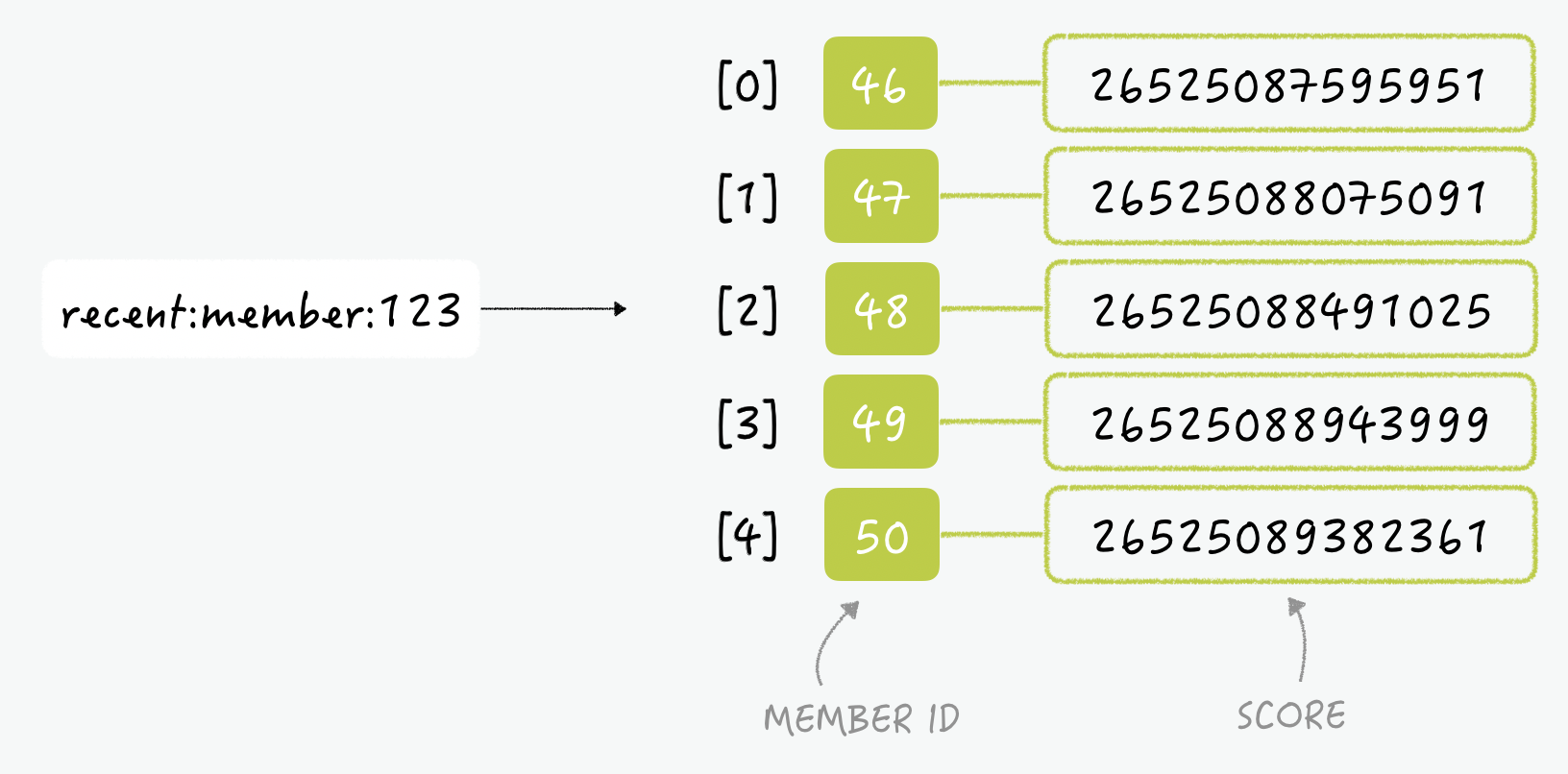
3. 최근 검색 목록 표시하기
이 기능을 관계형 데이터베이스를 이용해 구현하려면 아래와 비슷한 쿼리문이 필요합니다.
select * from KEYWORD where ID = 123 order by reg_date desc limit 5;
이 쿼리는 사용자가 최근에 검색했던 테이블에서 최근 5개의 데이터를 조회합니다. 하지만 이렇게 RDBMS의 테이블을 이용해서 데이터를 저장한다면 중복 제거도 해야하고, 멤버별로 저장된 데이터의 개수를 확인하고, 오래된 검색어는 삭제하는 작업까지 이루어져야 합니다.
따라서 애초에 중복을 허용하지 않고, 정렬되어 저장되는 레디스의sorted set을 사용하면 간단하게 구현할 수 있습니다. sorted set은 가중치를 기준으로 오름차순으로 정렬되기 때문에, 가중치로 시간을 사용한다면 이 값이 가장 큰, 나중에 입력된 아이템이 맨 마지막 인덱스에 저장됩니다.
@RestController를 추가해주면서 Getmapping등의 Mapping 주소를 받는다.
Test Code
private MockMvc mvc
//웹 API를 테스트할때 사용
mvc.perform(get("/hello")) // -> hello주소로 http get을 요청함
.andExpect(status().isOk()) // -> 결과의 상태를 검증함
.andExpect(content().string(hello)) //-> hello랑 콘텐츠의 결과값이 같은지 확인
Dto
생성자들을 처리해줌
@Getter
@Getter
@requiredArgsConstructor
public class HelloresponseDto{
private final String name;
private final int amount
}
TestCode
HelloResponseDto dto = new HelloResponseDto(name,amount);
assertThat(dto.getName()).isEqualTo(name) //테스트 검증 라이브러리
Controller에서도 Dto 사용하기
@GetMapping("/hello/dto")
public HelloResponseDto helloDto(@RequestParam("name") String name, @RequestParam("amount") int amount){
return new HelloResponseDto(name, amount);
}
Dto 사용한 controller 테스트
String name = "hello";
int amount = 100;
mvc.perform(
get("/hello/dto")
.param("name", name) //인자값 넣어주기
.param("amount", String.valueOf(amount)))
.andExpect(status().isOk))
.andExpect(jsonPath("$.name", is(name)))
.andExpect(jsonPath("$.amount", is(amount))); //jsonPath는 JSON 응답값을 필드별로 검증
//$를 기준으로 필드명 명시
게시판 만들기
domain 폴더는 게시글, 댓글, 회원, 정산, 결제 등 소프트웨어에 대한 요구사항 혹은 문제 영역
Posts클래스
@Getter
@NoArgsConstructor
@Entity // -> 테이블과 링크될 클래스임을 나타냅니다
public class Posts extends BaseTimeEntity {
@Id // -> PK인 것을 나타냅니다.
@GeneratedValue(strategy = GenerationType.IDENTITY) // -> auto_increment 추가
private Long id; //-> 왠만하면 Long으로 하기
@Column(length = 500, nullable = false) //-> 선언안해도 되는데, 추가되는 옵션 있으면 필수
private String title;
@Column(columnDefinition = "TEXT", nullable = false)
private String content;
private String author;
@Builder //-> 생성자 대신에 하는 것
public Posts(String title, String content, String author){
this.title = title;
this.content = content;
this.author = author;
}
public void update(String title, String content){
this.title = title;
this.content = content;
}
}
Redis는 Remote Dictionary Server의 약자로서, 키-값 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템입니다.
데이터베이스를 이용하면 데이터를 영속적으로 관리할 수 있지만, 입출력에 다소 시간이 걸리기 때문에 실시간 서비스에서는 더 적합한 저장소를 사용할 필요가 있습니다. 이 Redis는 메모리 기반의 저장소이기 때문에 필요한 정보를 빠르게 저장하고 가져올 수 있는 실시간 서비스에 적합한 저장소입니다.
Redis는 메모리 기반의 키-값(Key-Value) 저장소로, 쉽게 설명하면 메모리를 캐시처럼 사용하면서 데이터를 빠르게 입출력할 수 있도록 해주는 저장소입니다. 모든 데이터를 메모리에 저장하기때문에 읽기와 쓰기 명령이 매우 빠릅니다. 그런데 메모리는 휘발성이기 때문에 시스템이 꺼지면 모든 데이터가 날아가게 됩니다. 따라서 데이터를 지속적으로 유지하기 위해 모든 작업을 로그에 기록해서 디스크에 저장한 후, 시스템을 구동할 때 로그를 기반으로 데이터를 다시 메모리에 올리는 방식을 사용합니다.
따라서 전체 데이터를 영구히 저장하기보다는, 캐시처럼 휘발성이나 임시성 데이터를 저장하는 데 많이 사용됩니다. Casssandra나 HBase와 같이 NoSQL DBMS로 분류되기도 하고, memcached와 같은 In memory 솔루션으로 분류되기도 합니다.
메모리를 이용하여 고속으로 <key, value> 스타일의 데이터를 저장하고 불러올 수 있는 시스템 정도로만 이해하면 되겠습니다.
Redis 특징
1. Key/Value
2. 다양한 데이터 타입
String - 일반적인 문자열로 최대 512Mbyte 길이까지 지원, Text 문자열뿐만 아니라 Integer와 같은 숫자나 JPEG와 같은 Binary 파일까지 저장 가능
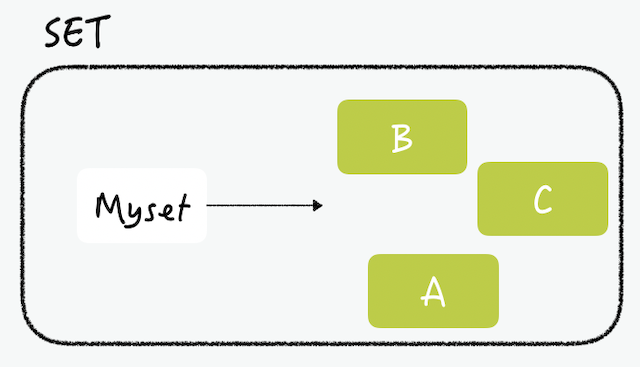
Set - String의 집합으로 여러 개의 값을 하나의 Value 내에 넣을 수 있음. 정렬되지 않은 집합형으로, 한 Key에 중복된 데이터는 존재하지 않음. Set에 포함된 요소의 수와 관계없이 일정한 시간으로 체크를 할 수 있는 것이 장점.
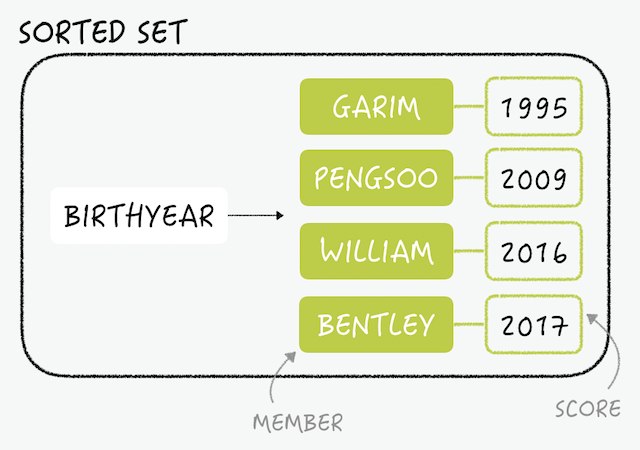
Sorted Sets - Set에 Score라는 필드가 추가된 데이터형으로, Score는 일종의 가중치. 데이터는 오름차순으로 내부 정렬되며, 정렬하는 기준이 Score. Score 값은 중복될 수 없음.
Lists - String의 집합으로 Set과 유사하지만 일종의 양방향 Linked List. List 앞과 뒤에서 push/pop 연산을 사용해 데이터를 추가 및 삭제가 가능.
Hashes - value에 field와 string value 쌍으로 이루어진 테이블을 저장. 객체를 나타내는 데 사용 가능. 형태는 List와 비슷하나 필드명, 필드값의 연속으로 이루어짐.
Redis 저장방식
레디스는In-Memory 데이터베이스입니다. 즉, 모든 데이터를 메모리에 저장하고 조회합니다. 기존 관계형 데이터베이스(Oracle, MySQL) 보다 훨씬 빠른데 그 이유는 메모리 접근이 디스크 접근보다 빠르기 때문입니다. 하지만 빠르다는 것은 레디스의 여러 특징 중 일부분입니다. 다른 In-Memory 데이터베이스(ex. Memcached) 와의 가장 큰 차이점은다양한 자료구조를 지원한다는 것입니다. 레디스는 아래처럼 다양한 자료구조를 Key-Value 형태로 저장합니다.
이러한 다양한 자료구조를 제공하면 왜 좋을까?
바로개발의 편의성과 난이도때문입니다.
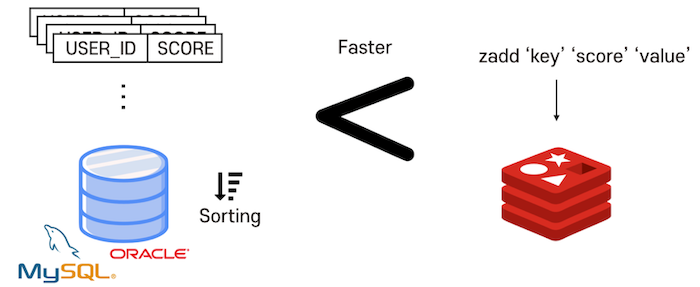
예를 들어 실시간 랭킹 서버를 구현할 때 관계형 DBMS를 이용한다면 DB에 데이터를 저장하고, 저장된 SCORE 값으로 정렬하여 다시 읽어오는 과정이 필요할 것입니다. 개수가 많아지면 속도가 느려질 텐데요, 이 과정에서 디스크를 사용하기 때문입니다. In-memory 기반으로 서버에서 데이터를 처리하도록 직접 코드를 짤 수도 있겠지만.. 레디스의 Sorted-Set을 이용하는게 더 빠르고 간단한 방법일 것입니다.
레디스는 트랜잭션의 문제도 해결해 줄 수 있습니다. 싱글 스레드로 동작하는 서버의 모든 자료구조는 atomic 하기 때문에, race condition을 피해 데이터의 정합성을 보장하기 쉽습니다.
즉, 외부의 Collections을 잘 이용하는 것만으로 개발 시간 단축이 가능하고, 생각하지 못한 여러가지 문제를 줄여줄 수 있으므로 개발자는 비즈니스 로직에 집중할 수 있다는 큰 장점이 존재합니다.
Redis의 자료구조
1. String
레디스의 string은 키와 연결할 수 있는 가장 간단한 유형의 값입니다. 레디스의 키가 문자열이므로 이 구조는 문자열을 다른 문자열에 매핑하는 것이라고 볼 수 있습니다.
> set hello world
OK
> get hello
"world"
2. List
일반적인 linked list 의 특징을 갖고 있습니다. 따라서 list 내에 수백만 개의 아이템이 있더라도 head와 tail에 값을 추가할 때 동일한 시간이 소요됩니다. 특정 값이나 인덱스로 데이터를 찾거나 삭제할 수 있습니다.
LPUSH mylist B # now the list is "B"
LPUSH mylist A # now the list is “A","B"
RPUSH mylist A # now the list is “A”,”B","A"
3. Hash
hash는 field-value 쌍을 사용한 일반적인 해시입니다. key에 대한 filed의 갯수에는 제한이 없으므로 여러 방법으로 사용이 가능합니다.
field와 value로 구성된다는 면에서 hash는 RDB의 table과 비슷합니다. hash key는 table의 PK, field는 column, value는 value로 볼 수 있습니다. key가 PK와 같은 역할을 하기 때문에 key 하나는 table의 한 row와 같습니다. 아래는 일반적으로 사용하는 RDB의 테이블을 레디스의 해시 구조로 나타낸 그림입니다.
4. set
set은 정렬되지 않은 문자열의 모음입니다. 일반적인 set이 그렇듯이, 아이템은 중복될 수 없습니다. 교집합, 합집합, 차집합 연산을 레디스에서 수행할 수 있기 때문에 set은객체 간의 관계를 표현할 때 좋습니다.
5. sorted set
sorted set은 set과 마찬가지로 key 하나에 중복되지 않는 여러 멤버를 저장하지만, 각각의 멤버는 스코어에 연결됩니다. 모든 데이터는 이 값으로 정렬되며, 스코어가 같다면 멤버값의 사전순서로 정렬됩니다.sorted set은 주로 sort가 필요한 곳에 사용됩니다.
6. 그 외의 것들
bit / bitmap:SETBIT,GETBIT등의 커맨드로 일반적인 비트 연산이 가능합니다. 비트맵을 사용하면 공간을 크게 절약할 수 있다는 장점이 있는데요, 이 내용은 다음번 활용사례에서 자세하게 말씀드리겠습니다.
hyperloglogs: 집합의 카디널리티(원소의 갯수)를 추정하기 위한 데이터 구조입니다. (ex. 검색 엔진의 하루 검색어 수) 일반적으로 이를 계산할 때에는 데이터의 크기에 비례하는 메모리가 필요하지만, 레디스의 hyperloglogs를 사용하면 같은 데이터를 여러번 계산하지 않도록 과거의 항목을 기억하기 때문에 메모리를 효과적으로 줄일 수 있습니다. 메모리는 매우 적게 사용하고 오차는 적습니다.
Geospatial indexes: 지구상 두 지점의 경도(longitude)와 위도(latitude)를 입력하고, 그 사이의 거리를 구하는 데에 사용됩니다. 내부적으로는 Sorted Set Data Structure를 사용합니다.
Stream: 레디스 5.0에서 새로 도입된로그를 처리하기 위해 최적화된 데이터 타입입니다. 차별화된 다양한 장점이 있지만, 가장 큰 특징은 소비자(Consumer)그룹을 지정할 수 있다는 것입니다. Stream에 대해서는 다음 기회에 더 자세하게 말씀드리겠습니다.
mongoDB는 문서지향(Document-Oriented) 저장소를 제공하는 NoSQL 데이터베이스 시스템으로, 현존하는 NoSQL 데이터베이스 중 인지도 1위를 유지하고 있습니다.
스키마 제약 없이 자유롭고, BSON(Binary JSON) 형태로 각 문서가 저장되며 배열(Array)이나 날짜(Date) 등 기존 RDMS에서 지원하지 않던 형태로도 저장할 수 있기 때문에 JOIN이 필요 없이 한 문서에 좀 더 이해하기 쉬운 형태 그대로 정보를 저장할 수 있다는 것이 특징입니다.
특히 mongoDB는 문서지향 데이터베이스로, 이것은 객체지향 프로그래밍과 잘 맞고 JSON을 사용할 때 아주 유용합니다. 따라서 자바스크립트를 기반으로 하는 Node.js와 호환이 매우 좋기 때문에, Node.js에서 가장 많이 사용되는 데이터베이스입니다. 물론 mysql 같은 관계형 데이터베이스 사용도 가능합니다.
문서지향 데이터베이스에서는 행 개념 대신 보다 유연한 모델인 문서를 이용하는데, 내장문서와 배열 따위의 표현이 가능해서 복잡한 객체의 계층 관계를 하나의 레코드로 표현할 수 있습니다. 이러한 문서지향 데이터베이스로는 mongoDB 이외에도 10gen, Couchbse, CouchDB 등이 있습니다.
mongoDB 특징
Join이 없으므로 Join이 필요 없도록 데이터 구조화가 필요
다양한 종류의 쿼리문을 지원(필터링, 수집, 정렬, 정규표현식 등)
관리의 편의성
스키마 없는(Schemaless) 데이터베이스를 이용한 신속 개발. 필드를 추가하거나 제거하는 것이 매우 쉬워짐
쉬운 수평 확장성
인덱싱 제공
mongoDB 구조
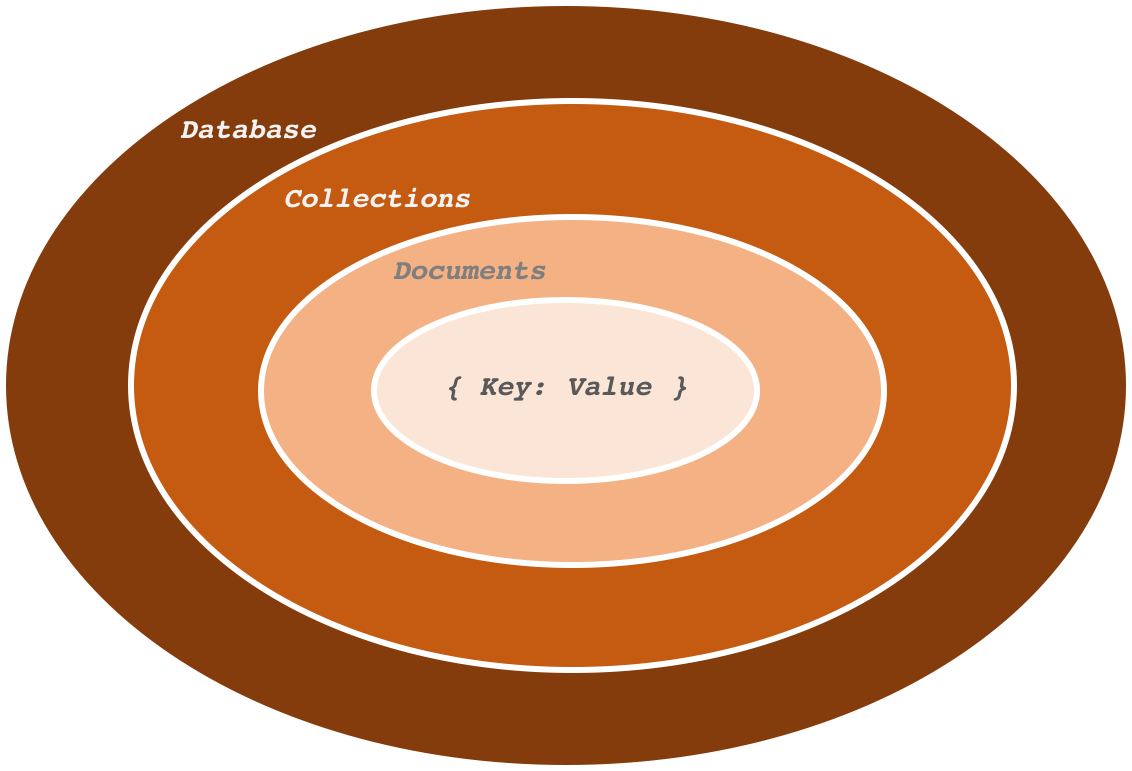
많은 DB가 있고 그 안에 컬렉션이 있고 컬렉션에는 여러개의 Document가 있음
Document는 동적 스키마를 갖고있기 때문에, 같은 Collection 안의 Document끼리 다른 스키마를 갖고 있을 수 있다. 즉, 서로 다른 데이터들을 가지고 있을 수 있다.
mongoDB 장단점
장점
쌓아놓고 삭제가 없는 경우가 가장 적합
Flexibility : Schema-less라서 어떤 형태의 데이터라도 저장할 수 있다.
Performance : Read & Write 성능이 뛰어나다. 캐싱이나 많은 트래픽을 감당할 때 써도 좋다.
Scalability : 애초부터 스케일아웃 구조를 채택해서 쉽게 운용가능하다. Auto sharding 지원
Deep Query ability : 문서지향적 Query Language 를 사용하여 SQL 만큼 강력한 Query 성능을 제공한다.
Conversion / Mapping : JSON형태로 저장이 가능해서 직관적이고 개발이 편리하다.
단점
정합성이 떨어지므로 트랜잭션이 필요한 경우에는 부적합
JOIN이 없다. join이 필요없도록 데이터 구조화 필요
memory mapped file으로 파일 엔진 DB이다. 메모리 관리를 OS에게 위임한다. 메모리에 의존적, 메모리 크기가 성능을 좌우한다.
SQL을 완전히 이전할 수는 없다.
B트리 인덱스를 사용하여 인덱스를 생성하는데, B트리는 크기가 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 저하된다. 이런 B트리의 특성 때문에 데이터를 넣어두면 변하지않고 정보를 조회하는 데에 적합하다
데이터 저장구조
MongoDB는 기본적으로 memory mapped file(OS에서 제공되는 mmap을 사용)을 사용한다. 데이터를 쓰기할때, 디스크에 바로 쓰기작업을 하는 것이 아니라 논리적으로 memory 공간에 쓰기를 하고, 일정 주기에 따라서, 이 메모리 block들을 주기적으로 디스크에 쓰기한다. 이 디스크 쓰기 작업은 OS에 의해서 이루어 진다.
OS에 의해서 제공되는 가상 메모리를 사용하게 되는데, 물리 메모리 양이 작더라도 가상 메모리는 훨씬 큰 공간을 가질 수 있다. 가상 메모리는 페이지(Page)라는 블럭 단위로 나뉘어 지고, 이 블럭들은 디스크 블럭에 매핑되고, 이 블럭들의 집합이 하나의 데이터 파일이 된다.
메모리에 저장되는 내용은 실제 데이터 블록과, 인덱스 자체가 저장된다. MongoDB에서 인덱스를 남용하지 말라는 이야기가 있는데, 이는 인덱스를 생성 및 업데이트 하는데 자원이 들어갈 뿐더러, 인덱스가 메모리에 상주하고 있어야 제대로 된 성능을 낼 수 있기 때문이기도 하다.
만약에 물리 메모리에 해당 데이터 블록이 없다면, 페이지 폴트가 발생하게 되고, 디스크에서 그 데이터 블록을 로드하게 된다. 물론 그 데이터 블록을 로드하기 위해서는 다른 데이터 블록을 디스크에 써야한다.
즉, 페이지 폴트가 발생하면, 페이지를 메모리와 디스카 사이에 스위칭하는 현상이 일어나기 때문에 디스크IO가 발생하고 성능 저하를 유발하게 된다.
즉 메모리 용량을 최대한 크게 해서 이 페이지폴트를 예방하라는 이야기이다. 그러나, 페이지 폴트가 아예 발생 안할 수는 없다.(1TB의 데이터를 위해 메모리를 진짜 1TB만큼 올릴 수는 없다.) 그래서 페이지 폴트를 줄이는 전략으로 접근 하는 것이 옳은 방법이다.
페이지 폴트시 디스크로 write되는 데이터는 LRU 로직에 의해서 결정된다. 그래서, 자주 안쓰는 데이터가 disk로 out되는데, 일반적인 애플리케이션에서 자주 쓰는 데이터의 비율은 그리 크지 않다. 이렇게 자주 액세스되는 데이터를 Hot Data라고 하는데, 이 데이터들이 집중되서 메모리에 올라가도록 Key 설계를 하는 것이 핵심이다. 전체 데이터를 scan하는 등의 작업을 하게 되면, 무조건 페이지 폴트가 발생하기에 table scan이 필요한 시나리오는 별도의 index table(summary table)을 만들어서 사용하는 등의 전략이 필요하다.
구성요소
mongoDB는 데이터를 관리하기 위한 형식으로 데이터 입출력 시에는 JSON 형식을 사용하고 데이터 저장 시에는 BSON 형식을 사용합니다. 다음은 JSON과 BSON 형식에 대한 자세한 내용입니다.